C’est au début des années 90 qu’est apparu le langage XML. Au départ il était principalement destiné à l’échange de fichiers sur le web. Mais aujourd’hui, son utilisation va bien au delà.
La principale raison de notre orientation vers le XML est l’exportation de données simplifiée vers d’autres applications, comme un logiciel de cartographie, par exemple.
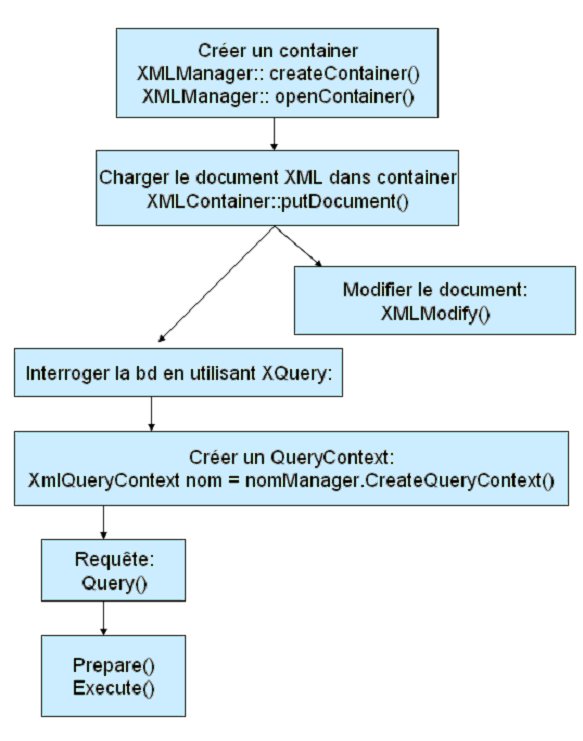
Après avoir utilisé les langages de requêtes comme XQuery ou Xpath, ne permettant uniquement que de lire un document, nous nous sommes orientés vers le parseur Xerces.
Nous avons finalement opté pour une solution plus adaptée aux contraintes de notre système : embarqué.
Nous avons choisi la base de données XML native : BerkleyDB XML. Sa particularité est d’avoir été conçu pour des applications embarquées. De plus Berkley est déjà une référence dans le domaine des bases de données puisque Berkeley DB est intensivement utilisé par Google pour la gestion des « Google accounts », les sésames d’accès à ses services, du courrier électronique jusqu’à la messagerie instantanée et l’hébergement de fichiers.
Voici le principe de fonctionnement de BerkleyDB XML :
Il est donc possible soit de modifier un document soit de l’interroger. Il est même possible de créer un document de toute pièce avec la méthode : XMLDocument ::createDocument() ; Toutefois, une fois qu’un container a été crée et ouvert toutes les modifications qui peuvent être apportées par le programme ne sont apportées qu’au fichier dbxml et non au document XML. Il faut donc créer une fonction qui génère un fichier XML à partir du fichier dbxml.
C’est ce que nous avons réalisé notamment à travers cet algorithme :
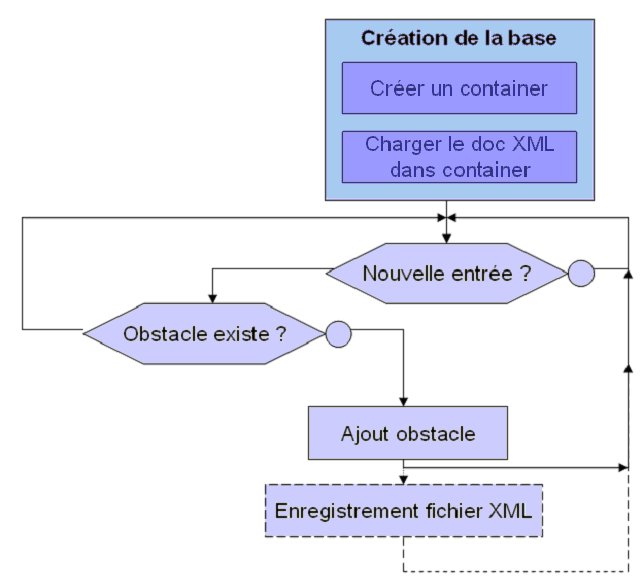
La partie enregistrement de fichier XML est une tâche qui s’exécute lorsque l’utilisateur quitte l’application. Dans l’absolu, si l’on considère que notre application ne s’arrête jamais et que l’on se contente du fichier dbxml, il n’est pas nécessaire de faire une sauvegarde de la base sous forme d’un fichier XML. Cependant par mesure de sécurité, nous avons préféré conserver une sauvegarde de la base, lors de la fermeture de l’application.
La base de donnée est donc crée à l’ouverture de l’application, à partir de la dernière sauvegarde du fichier XML. Nous travaillons ensuite directement sur la base de donnée, c’est à dire sur le fichier dbxml.
A chaque nouvelle obstacle détecté, une balise

{Consulter} l'article.
La détection des arêtes consiste essentiellement à repérer les changements locaux d’intensité.
La dérivée, ou le gradient dans le cas des fonctions à plusieurs dimensions, est tout à fait désignée dans un tel cas. Puisqu’une image est une fonction discrète, des méthodes de différences finies sont utilisées pour le calcul du gradient. Les algorithmes de détection d’arête sont constitués de trois étapes :
 Filtrage : La dérivée est très sensible au bruit ; une image doit donc être filtrée afin de ne pas générer trop de fausses arêtes. Cependant, le filtrage diminue aussi la réponse de l’algorithme pour les arêtes réelles. Il y a donc un compromis entre la diminution du bruit et la conservation des arêtes.
Mise en valeur : Il s’agit de faire ressortir les arêtes. C’est à cette étape que le gradient est calculé.
Détection : L’algorithme doit pouvoir déterminer, pour chaque pixel, si le gradient y est suffisamment grand pour être sur une arête.
Filtrage : La dérivée est très sensible au bruit ; une image doit donc être filtrée afin de ne pas générer trop de fausses arêtes. Cependant, le filtrage diminue aussi la réponse de l’algorithme pour les arêtes réelles. Il y a donc un compromis entre la diminution du bruit et la conservation des arêtes.
Mise en valeur : Il s’agit de faire ressortir les arêtes. C’est à cette étape que le gradient est calculé.
Détection : L’algorithme doit pouvoir déterminer, pour chaque pixel, si le gradient y est suffisamment grand pour être sur une arête.
a. Approche gradient Les points de contour dans une image sont caractérisés par des extrema locaux du gradient. Une première approche consiste donc à : 1. calculer la norme du gradient en tous point de l’image, 2. sélectionner les pixels à l’aide d’un seuil fixé a priori pour la norme du gradient.
Pour la détection des contours, deux quantités reliées au gradient sont importantes, la norme et la direction. Des différentes dérivées discrètes du gradient, on peut ressortir deux masques correspondants aux directions orthogonales :
Gx =
| 0 | 0 | 0 |
| -1 | 0 | 1 |
| 0 | 0 | 0 |
Gy =
| 0 | -1 | 0 |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
Les opérateurs simples sont trop sensibles au bruit. Il existe plusieurs filtres moyenneurs directionnels permettant d’atténuer ce problème, par exemple :
Opérateur de Prewitt
Gx =
| -1 | 0 | 1 |
| -1 | 0 | 1 |
| -1 | 0 | 1 |
Gy =
| -1 | -1 | -1 |
| 0 | 0 | 0 |
| 1 | 1 | 1 |
Opérateur de Sobel
Gx =
| -1 | 0 | 1 |
| -2 | 0 | 2 |
| -1 | 0 | 1 |
Gy =
| -1 | -2 | -1 |
| 0 | 0 | 0 |
| 1 | 2 | 1 |
Cet opérateur est assez populaire et correspond à une convolution de l’image par : [1 2 1] * [-1 0 -1]
b. Approche laplacien Le seuillage des images gradient dans les directions x et y donne des contours assez forts dans ces directions, cependant ils ne sont pas isotropes. Si l’on est sensible à cela, on utilise un opérateur Laplacien qui lui est invariant aux rotations de l’image et permet de faire ressortir des contours dans toutes les directions. Néanmoins, la sensibilité au bruit est accrue par rapport au gradient.
| -1 | -1 | -1 |
| -1 | 8 | -1 |
| -1 | -1 | -1 |
ou
| 0 | -1 | 0 |
| -1 | 4 | -1 |
| 0 | -1 | 0 |
c. Convolution « adaptée » Cette technique basée sur la convolution produit une description des lignes minces dans une image d’entrée. Cet opérateur que nous nommerons détection de lignes permet en adaptant la convolution de détecter les lignes d’une largeur définie dans une certaine orientation :
Horizontales :
| -1 | -1 | -1 |
| 2 | 2 | 2 |
| -1 | -1 | -1 |
Verticales :
| -1 | 2 | -1 |
| -1 | 2 | -1 |
| -1 | 2 | -1 |
Obliques (+45°) :
| -1 | -1 | 2 |
| -1 | 2 | -1 |
| 2 | -1 | -1 |
Obliques (-45°) :
| 2 | -1 | -1 |
| -1 | 2 | -1 |
| -1 | -1 | 2 |
Ces masques sont obtimisés pour la détection de lignes claires sur fond foncé, si l’on cherche à faire ressortir des lignes foncées sur fond clair, il faut inverser les valeurs.
d. La transformée de Hough L’application la plus simple permet de reconnaître les lignes d’une image, mais des modifications peuvent être apportées pour reconnaître n’importe quelle forme : c’est la transformée généralisée de Hough. Le principe de la transformée de Hough est qu’il existe un nombre infini de lignes qui passent par un point, dont la seule différence est l’orientation (l’angle). Le but de la transformée est de déterminer lesquelles de ces lignes passent au plus près du schéma attendu.
Afin de déterminer que deux points se trouvent sur une même ligne potentielle, on doit créer une représentation de la ligne qui permet une comparaison dans ce contexte. Dans la transformée de Hough, chaque ligne est un vecteur de coordonnées paramétriques : ρ : la norme du vecteur θ : l’angle
En transformant toutes lignes possibles qui relient un point à un autre, c’est à dire en calculant la valeur de ρ pour chaque θ, on obtient une sinusoïde unique appelée espace de Hough. Si les courbes associées à deux points se coupent, l’endroit où elles se coupent dans l’espace de Hough correspond aux paramètres d’une droite qui relie ces deux points.
Calcul des coordonnées paramétriques : On utilise pour cela la formulation généralisée d’une droite : ρ = x cos α + y sin α. L’orientation locale φ du contour peut être calculée par : φ = arctg (Gy / Gx) où Gx et Gy sont déterminés par l’application d’un opérateur Gradient (Sobel par exemple). Pour chaque point (x,y) dans l’image, il y a exactement un point (φ,ρ) dans l’espace de Hough. Si on additionne la norme du gradient à ce point, les contours forts sont mieux représentés.
{Consulter} l'article.
Comment après détection d’un panneau, identifier sa signification ? C’est ce que nous allons voir à travers cet article.
Après avoir détecté un panneau, l’application doit maintenant le differencier en le comparant aux modèles présents dans la base de données.
Le premier problème qui se pose est relatif à la taille du panneau détecté : pour pouvoir être comparés, les panneaux doivent être ramenés à une taille standard. La taille retenue est de 32x32 pixels, compromis empirique entre la quantité d’informations préservée et la taille de l’image à traiter.
La réduction à une image de 32*32 pixels se fait de la façon suivante : on calcule le ratio de la réduction (largeur de l’image / 32) puis on prend pour chaque pixel de l’image d’arrivée de coordonnées X et Y son équivalent dans l’image de base (X * ratio) et (Y * ratio). Aucune interpolation (ni linéaire ni cubique) n’est effectuée de façon à garantir un temps d’execution relativement faible.

Maintenant que les panneaux sont techniquement comparables (car de même taille) il faut d’une part isoler la partie du panneau qui le caracterise le plus et d’autre part tenter d’accentuer au maximum les caractères propres à chaque panneau pour faciliter la comparaison.
Tous les panneaux à détecter étants des panneaux d’interdiction, on remarque vite qu’ils se differencient uniquement par l’information contenue en leur centre. On effectue donc une extraction de nôtre image en ne gardant qu’un coeur de 22x22 pixels, c’est à dire le panneau moins le contour rouge signifiant une interdiction.
Il faut ensuite comparer l’image obtenue avec la bibliotheque de panneaux. L’application traite pour cela au préalable les images pour réduire au maximum l’information tout en préservant un minimum essentiel pour differencier les panneaux. On effectue ainsi une binéarisation : tous les pixels sous un seuil fixé (127 de rouge et 127 de bleu et 127 de vert) sont mis en noir, les autres sont mis en blanc.

L’image est ensuite comparée pixel par pixel à celles contenues dans la bibliotheque. On en déduit un taux de similarité. Par exemple si sur les 484 pixels de l’image (22*22) 346 sont semblables à une image de la bibliotheque le taux de similarité est de 346 / 484 = 72%
Si le meilleur taux de similarité d’une image avec celles de la bibliothèque est superieur à 90%, l’image est déclarée comme reconnue.

{Consulter} l'article.
Lien vers le second site de présentation de notre projet.
Nous venons de mettre en place un site bilingue dont le rôle est de présenter officiellement notre projet.
http://u-cergy.com/siic_camion/
L’avancement de notre projet continuera néanmoins à être expliqué sur http://clairiere.free.fr
{Consulter} l'article.
J’ai essayé ici de dresser un comparatif des différents types de capteurs environnementaux existant sur le marché afin de déterminer leur éventuelle utilité dans notre projet.
Dans cette étude, j’ai uniquement considéré les capteurs qui nous permettront de connaître la configuration de l’environnement direct, au travers de la détection de la signalisation routière ainsi que des infrastructures.
I. Les télémètres
Les télémètres permettent de mesurer la distance d’un objet. D’autres utilisations sont possibles, comme par exemple une mesure de vitesse. Il existe quatre types de télémètres :
1. télémètres à ultrasons : La valeur de distance est obtenue en mesurant le temps de vol d’un signal ultrasonore. Ce type de télémètre utilise un émetteur couplé à un récepteur piézo-électrique pour générer et recevoir l’onde sonore. Avantages : Simple, économique (systèmes industriel à partir de 45), peu encombrant (émetteur-récepteur piézo-électrique = 1cm de diamètre) Inconvénients : Les ultrasons ne sont pas directifs, donc pas de positionnement précis à grande distance. La vitesse de propagation de l’onde sonore est dépendante des conditions météo, pour calculer une vitesse il faut donc actualiser les calculs en fonction. Utilisations possibles : détection d’obstacles à grande distance ou à vitesse basse.
2. télémètres à infrarouges : Considéré comme la version « bon marché » du télémètre laser. Le principe repose sur l’émission d’un faisceau infrarouge modulé et sur la réception du faisceau réfléchie sur un récepteur déporté. Le calcul de la distance se fait par triangulation. Avantages : capteur directif, peu encombrant (plus petit qu’un télémètre à ultrason), nécessite peu d’énergie (mW) et est indépendant des conditions extérieures. Inconvénients : Porté limitée à moins d’un mètre. Utilisations : petits robots.
3. télémètres laser : Ce type de capteur utilise un faisceau laser pour mesurer les distances. Deux types de mesures peuvent être réalisées, suivant l’utilisation souhaitée. Pour des portées courtes, (moins d’un mètre), on utilise des télémètres à triangulation sui offrent une très grande précision pour une plage de mesure réduite. On retrouve ici le principe des télémètres infrarouges à triangulation. Les télémètres à corrélation de phase ont une plus faible résolution mais une plage de mesure de l’ordre de plusieurs kilomètres. Le défaut de ce type de matériel est un temps de réponse de l’ordre de plusieurs millisecondes. Les avantages d’un faisceau laser sont qu’ils sont directifs, très rapides, et peu sensible aux conditions atmosphériques. La mesure de la distance se faisant sur le principe du temps de vol du faisceau, le problème de réflectivité de la cible ne se pose plus (celle-ci doit toute fois être suffisamment grande pour réfléchir le faisceau incident).
Ce type de capteur est très directif (un point). Pour y remédier, on utilise des télémètres lasers à balayage. Le faisceau laser est émis sur un miroir rotatif, ce qui permet de balayer l’espace sur un large plan. L’inconvénient de ce type de fonctionnement est de nécessiter plus de mécanique, donc un encombrement plus important et une plus grande fragilité. Enfin le prix est élevé, du fait de l’horloge extrêmement précise et de la mécanique fiabilisée.
4. Radar : On se base ici sur le radar Doppler, le seul type utilisé dans le domaine de l’automobile. La vitesse relative de la cible par rapport à un autre véhicule est déterminée en mesurant la déviation en fréquence de l’écho. Le problème de ce type de radar, est qu’ils offrent un angle d’ouverture très faible. De plus les opérations de filtrage des signaux joue sur le temps de réponse du système. Pour compenser ces problèmes, certains projets fusionnent les informations obtenues avec un radar et celles obtenues avec un télémètre. De cette façon, ils peuvent couvrir un champ plus large.
II. Les caméras
Outre l’utilisation des caméras dans la reconnaissance des panneaux routiers que nous détaillons dans l’article "détection des panneaux", les caméras offrent plusieurs possibilités en ce qui concerne la détection d’obstacles.
1. Stéréovision Grâce à l’utilisation de plusieurs caméras, on obtient une carte tridimensionnelle de l’environnement. Le défaut de ce type de procédé est d’être extrêmement lourd en terme de calcule et de contraintes d’implémentation (paramètres des caméras constants au cours du temps)
2. Reconnaissance de formes Ce procédé est en deux étapes, reconnaissance de formes, puis exploitation des caractéristiques de l’obstacle pour rétro projeter son image dans la scène 3D et ainsi obtenir sa position. Ce type de traitement est rapide, performant et assez simple à implémenter. Néanmoins cette technique est bien moins précise que des données obtenues grâce à un télémètre, elle est actuellement utilisée au centre robotique et dans beaucoup d’autres laboratoires de recherche. En terme de coût, cette méthode a l’avantage d’être bien moins chère que pour un télémètre. On peut utiliser des caméras assez courantes d’un prix de quelques centaines d’euros contre des milliers d’euros pour un télémètre. De plus comme précisé précédemment, ce capteur sera aussi utilisé pour d’autres applications.
Dans le cadre de notre projet, il nous est demandé de pouvoir mesurer la hauteur d’un pont. Si notre premier choix s’était orienté sur l’utilisation d’un télémètre à balayage laser, au regard de cet article et d’une étude de prix réalisée au près de revendeurs, nous penchons à présent pour l’utilisation d’une caméra. Il semble, toujours d’après cette étude, relativement aisé de déterminer des distances à partir des images. Afin de vérifier cette hypothèse, nous nous pencherons plus en détail sur ce procédé.
{Consulter} l'article.
Pour voir notre planning prévisionnel : ouvrir le fichier excel...
{Consulter} l'article.
Premiers choix techniques pour l’ensemble du projet.
L’objectif du projet est l’établissement d’une carte embarquée dédiée aux véhicules lourds. Cette carte doit recenser les obstacles tels que des ponts ou des interdictions spécifiques aux camions. Elle prendra principalement en compte la taille, la longueur, le poids du véhicule.
Dans chaque véhicule se trouvera un système d’acquisition embarqué composé :
d’un ordinateur de bord : localisation GPS, vitesse du véhicule,
d’un appareil d’acquisition d’images.
La détection des panneaux sera réalisée via une webcam et une transformée de Hough. Le calcul de la position du panneau ou du pont se fera ainsi :

OA = (OA1*AB) / A1B1
En ce qui concerne la détection des ponts, nous allons travailler sur des modèles par :
segmentation d’objets,
décomposition en graphes relationnels attribués (ARG).
Segmentation des objets :
transformée de Hough pour détection des lignes horizontales,
extraction des contours via utilisation du gradient morphologique,
algorithme de la Corde,
interconnexion des rectangles par méthode de prolongation,
décomposition des rectangles en segments, via algorithme d’amincissement décrit par Zhang-Suen.
{Consulter} l'article.
Présentation du sujet initial du projet
Aujourd’hui, la logistique du transport laisse une large part à l’informatique. Concernant l’informatique embarquée, proposer la meilleure route aux chauffeurs, en fonction d’une connaissance des contraintes dont leur véhicule dispose, est un réel enjeu.
Le but de ce projet serait de réaliser un prototype permettant à un véhicule
de mesurer la hauteur d’un obstacle (le véhicule passe sous un pont )
de situer cet obstacle grâce à un système GPS
d’assurer la mise à jour d’une carte d’obstacles afin de permettre aux chauffeurs d’une même flotte de savoir quelles sont les voies qu’ils peuvent emprunter en fonction des contraintes de hauteur de leur propre véhicule.
Le but est donc d’intégrer notre système d’évitement d’obstacle sur les véhicules d’une compagnie de transport routier. L’objectif est de guider le chauffeur automatiquement en fonction des trajets effectués précédemment.
Notre produit embarqué fonctionnera avec un logiciel de gestion capable de gérer et de communiquer avec une flotte de véhicule. La communication (GSM) permettra la mise à jour des données.
Ordinateur de bord : Pour la gestion et la centralisation des informations
Détecteurs : Pour repérer les panneaux et les obstacles par exemples. Ils peuvent être de plusieurs types, caméras, télémètres...
Récepteur GPS pour pouvoir localiser le véhicule.
GPRS pour la communication avec le reste de la flotte
Possibilité d’enregistrer et de modifier le profil du véhicule. Dans le cas où on change de remorque par exemple.
{Consulter} l'article.
Rechercher sur ce site :